
CIO Checklist
Here are the most common questions CIOs ask, along with explanations of how various components of Eyeris’ service address those questions. Just the facts, without marketing spin.
A. Deployment and Sovereignty
A1. Where does Eyeris run?
In a private cloud. In all cases, each Eyeris customer is served entirely within a dedicated, single-tenancy “walled garden” – meaning every service, compute, and storage used end-to-end in the data lifecycle resides entirely inside the boundary of that garden. Zero ingress/egress except as explicitly contracted, and zero reliance on external apps or services – including LLM processing. Everything is entirely private and entirely dedicated to a single eyeris customer.
This table provides a summary of the physical architecture beneath each functional layer of the service.
| Layer | Compute | Processing Storage | Continuity |
|---|---|---|---|
| Stella | High-GPU Array | Elastic, Ephemeral | Snapshot to S3/Blob/GCS |
| Luna | High-CPU Array | I/O Optimized, Ephemeral | Snapshot to S3/Blob/GCS |
| Sola - CI Data & Metadata |
Cloud-scale analytic warehouse service | Cloud-scale analytic warehouse service | Snapshot on S3/Blob/GCS |
| - CI Processing | High-CPU Array | I/O Optimized, Ephemeral | Snapshot to S3/Blob/GCS |
| - Data Collection | Light-duty Array | S3/Blob/GCS, Persistent | Replication on S3/Blob/GCS |
A2. Which cloud platforms are supported (AWS, Azure, GCP)?
All three.
A3. Can we pin processing to specific regions for data-residency obligations?
Each client can define the region in which their Eyeris service runs. All layers of the service (Stella, Luna, Sola) run in the same region.
A4. Does any customer data leave our tenancy at any stage?
Never.
B. Data Handling
B1. What data does Eyeris ingest, and what does it persist?
Eyeris uses raw operational data from many sources at the customer. That data can come from databases, cloud applications, data lakes, log streams, and batch processes. It can be pulled actively by Eyeris active collectors or pushed to Eyeris’ passive collectors by system owners at the customer. In all cases, data feeds are governed by signed data interchange contracts that specify the nature, timing, content, and format of transmissions – whether those transmissions are push or pull.
B2. Is raw data copied or processed in place?
Eyeris works with raw copies of source data. We do not use customer-host compute for any of our processing.
B3. What is the retention model, and can we set it?
Each customer specifies in their contract how long Eyeris retains each genre of data. Typically, source data are retained in secure archive for 3 months, Causal Intelligence data are maintained for a rolling 36-60 months, and end-user analytic interactions (conversations, data, charts, reports, etc.) are retained for 60 months.
B4. On contract end, what is the deletion guarantee and timeline?
All data are deleted from active storage and archive storage, and all drives are sanitized by Eyeris prior to returning those machines to the cloud pool, where they are again sanitized by the cloud platform itself.
C. Security Architecture
Eyeris’ platform security controls by functional layer are shown in the diagram below. A full recital of our SOC2 commitments on Security, Confidentiality, and Privacy is available by download at the bottom of this page.
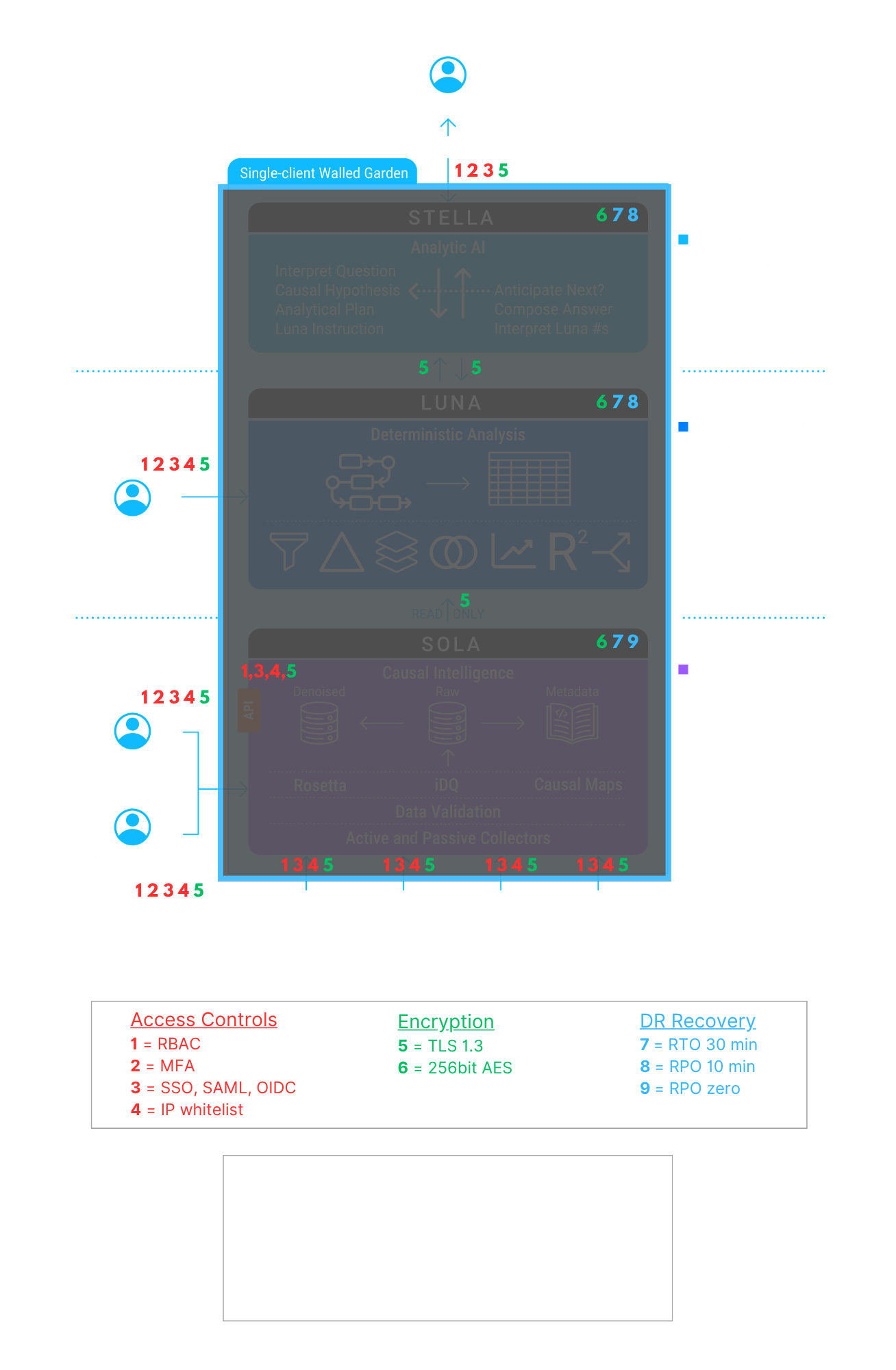
C1. Encryption in transit and at rest?
All data in-flight across the service boundary, including system-to-user and source-to-system transmissions, are encrypted using TLS 1.3. All data on disk are encrypted using 256-bit AES.
C2. Customer-managed keys supported?
CMK is supported as an option, subject to an upcharge and reduced SLAs. Integrated single-dependency processes are inherently cheaper and more reliable, but we recognize that some customers’ operating environments pose unique demands.
C3. Identity model — SSO, SAML/OIDC, MFA, SCIM?
Eyeris supports SSO, SAML/OIDC, and MFA. SCIM is less relevant for the Eyeris stack due to (a) its zero-ingress/zero-egress walled garden architecture and (b) its typical user community of a couple dozen high-impact executives.
C4. RBAC granularity — who can see which causal maps, inputs, outputs?
Access to and rights within each layer of the service architecture are controlled by role. Within Stella, only the user can see their own conversation history and analytical artifacts unless that user chooses to share those items with another user. Within Luna, only the Analytic Auditor has direct access to workflows for reports specifically shared with the AA by an executive user, and this access is read-only. Within Sola, no client personnel have operational access to the Intelligence Processing layer (Rosetta, iDQ, and Causal Maps), but client DBAs often have read access to the Sola CI repository via the API.
C5. Audit logs — events, retention, exportable to our SIEM?
Eyeris logs every interaction between the system and each user, every data flow checkpoint, and every change in access controls. All logs are available to the customer upon request. Realtime logging into SIEM is usually not necessary, given that the Eyeris service is a zero-ingress/zero-egress walled garden with only a couple dozen high-impact executive users.
D. AI Security
D1. Do LLMs or ML models touch our data? If so, which, with what boundaries?
No public LLM or ML models touch client data. Stella, Eyeris’ LLM, is a private walled garden implementation using an open-source semantic model locally installed and managed by Eyeris alone. No calls, dependencies, or trace/audit messages are allowed egress from the walled garden.
D2. Is our data used to train any shared model?
Customer data are not used in any way to train any semantic models.
D3. How are causal inferences validated to prevent silent model drift?
Sola uses a Structured Causal Modeling (SCM) approach, in which the baseline causal maps are defined deterministically by an Eyeris Causal Engineer. This SCM is executed prior to any neural processing and becomes the baseline against which any neural inferences might be applied, mitigating drift by providing a stable baseline of causal expression. Furthermore, neural inference in Stella is constrained to two problem domains: (1) translating natural language expressions of curiosity or analytical interest from the user into an analytical plan that connects that interest to the available CI data resources and (2) interpreting the results returned by the analysis and creating effective communication strategies to ensure the user understands what those data say. The analyses themselves may only be executed by Stella using Luna’s standard deterministic, auditable, traceable, human-interpretable analytic widgets. This architecture radically reduces the opportunity for inference instability.
E. Reliability
E1. SLA?
Each customer contract specifies the cadences of data transmission and intelligence processing for Sola, as well as system availability and performance for the CI API and the user-accessible functions of Stella and Luna.
E2. Backup and disaster-recovery posture — RPO/RTO?
These vary by layer. Please see the graphic in the Security section above for the DR/recovery standards for each functional layer.
E3. Incident response process and notification SLA?
We notify clients of any incident or failure against any SLA within 2 hours of detection.
F. Integration and IT Fit
F1. Supported source systems and connectors?
| Active Collectors | Passive Collector Standards |
|---|---|
Application-specific Data Integrations
Generic Data Integrations
|
|
F2. APIs for causal outputs — schemas, rate limits, auth?
The Causal Intelligence repository is accessible, upon customer request, through an ODBC/JDBC API. We do not charge for API access or usage. This includes access to the schemas, dictionaries, and CI tables. There are no rate limits applied, but we do require a performance waiver in the event that excessive API interrogation impacts core system performance relative to its SLAs.
F3. How is Eyeris integrated with our BI, warehouse, and MDM?
Eyeris does not use anything in your BI layer. No views, reports, applications, dashboards, etc. We often use portions of a customer’s existing MDM service, particularly around customer and product. For warehouses, it’s a mixed bag. If the warehouse contains minimally-processed event records from the OSS, we can use that as a source if customer IT wants to avoid incremental load on the OSS. But, our preference is always to source from as far upstream as possible, to avoid information loss from intermediate processing.
F4. Installation and onboarding — what do we stand up?
If all of your data are in systems to which we have integrations, and if you authorize active collection, there’s nothing you need to stand up on your side. However, there is almost always at least one important system running on-prem, and in many cases those are systems that IT needs to protect from external demands. So, you will need to create a transmission staging area that can be linked to our receiving staging area, so that you can manage the transmission of input data from those remaining systems to us.
F5. Time-to-first-result from contract signature?
It depends upon the scope of the implementation. For a single ERP, single SFA, single CRM, a few billing systems, accounting, payroll, and event log streams from a few operational processes, you can expect 3-5 months from contract to UAT. More systems, more time. Less systems, less time.
G. Causal-intelligence Methodological Risk
G1. How do you prevent spurious correlations entering the causal map?
First, as mentioned in D3 above, the causal maps are not inferred. They are explicitly defined. Inferences still happen, but they are restricted by the stable picture provided by the Structured Causal Models that are managed by the Causal Engineers. Second, that management process updates and refines the SCMs using denoised Causal Intelligence. Denoising in Sola actively identifies outliers using process control modeling, preventing outliers from (a) biasing the SCM or (b) stimulating an inappropriate fixation by Stella’s LLM.
G2. What governance exists to ensure executives are operating on valid information?
Every user interaction with Stella is fully logged. Every comment, prompt, response, artifact, report – all tied together in a package. That interaction package is directly attached to the Luna analytic workflow that Stella composed to build the data necessary to support a good answer to the user’s interrogation. The Luna workflow is composed exclusively of a handful of deterministic, human-interpretable, auditable widgets with complete end-to-end lineage tracing on every data element – from delivered report all the way down through the Luna workflow AND then all the way back through the Sola pipeline.
Luna also provides a WYSIWYG interface for a human Analytic Auditor to step through each transformation, manipulation, and calculation in any workflow. We recommend such a human audit prior to all significant actions, as this is how the organization builds trust in Stella. So, the governance process in Stella/Luna/Sola is organized around quick validation of a specific analysis on which an executive wants to act.
Additional technical details on Eyeris’ Causal Intelligence service, including SOC2 Commitments, client data ownership attestation, and delineation of Eyeris/Client responsibilities, are available here.